Como Eu Melhoraria a Performance de uma API de Alto Tráfego
Primeira coisa, eu não começo mudando código direto. Eu preciso entender como a API se comporta do INÍCIO até o FIM.
Então eu MEÇO (chave).
Eu usaria ferramentas como .NET benchmarking (Stopwatch é RUIM!), além de logs, gráficos, insights do Azure Monitoring, Google Analytics e Cloudflare Dashboard para ver o que realmente está lento. Nada de adivinhação — eu quero saber onde o tempo está sendo gasto.
Entendendo o Gargalo
Depois disso, eu separo em dois tipos principais:
- Operações de I/O
- Processamento de CPU
Para I/O, eu olho coisas como:
- Consultas no banco de dados
- Chamadas para APIs externas
- Acesso a disco/arquivos
Para CPU:
- Loops
- Processamento de dados
- Qualquer cálculo pesado
Isso me ajuda a saber onde focar.
Melhorias no Código
Agora eu começo a melhorar o código em si.
Se for I/O pesado:
- Garantir que tudo que pode ser assíncrono seja realmente async
- Evitar bloquear threads
Se for CPU pesado:
- Usar programação paralela quando fizer sentido
Também é importante ver quantas threads o servidor tem para usar bem bibliotecas como Parallel.ForEach
Usar GPU para paralelismo é algo para casos MUITO extremos. Eu nunca precisei usar, mas existe esse campo chamado computação em GPU para uso geral.
Eu também reviso:
- Estruturas de dados (tentar sair de O(n) para O(1) quando possível), e hoje a IA pode ajudar a identificar melhorias
- Uso de memória e pressão no garbage collector
- Em vez de usar class, às vezes dá para usar record ou struct
- Estruturas imutáveis sempre trazem ganhos, mesmo que pequenos — mas com 100.000 usuários por segundo isso faz diferença
Às vezes pequenas mudanças já trazem grandes ganhos.
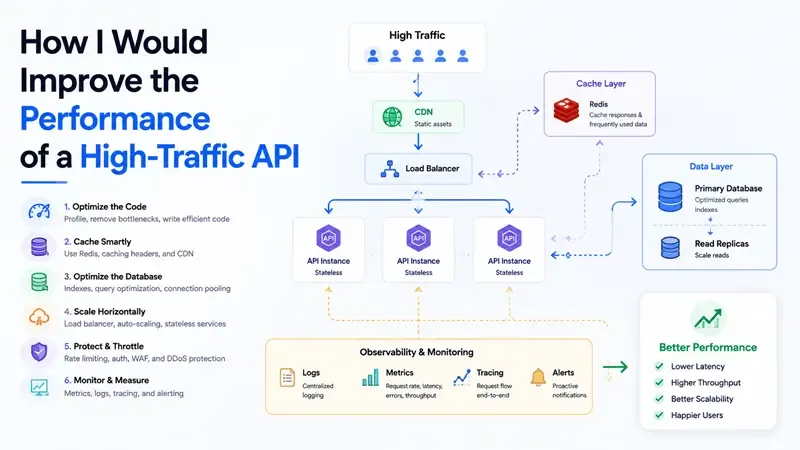
Reduzindo Carga com Cache
Se a API está recebendo muitas requisições, cache ajuda muito.
- Usar Redis como cache distribuído
- Cachear respostas que não mudam com frequência
- Usar arquivos estáticos quando possível
Isso sozinho já pode tirar uma grande carga do sistema.
Payload e Comunicação
Se o payload está muito pesado, eu tento reduzir.
Em alguns casos, trocar REST por gRPC pode ajudar bastante, reduzindo o tamanho do payload (às vezes até uns 40%).
Nem sempre é necessário, mas é uma opção.
Otimização de Banco de Dados
Muitos problemas de performance vêm do banco.
- Analisar queries
- Reescrever quando necessário
- Reduzir joins desnecessários
- Entender como os dados estão sendo acessados
Se fizer sentido, posso mudar a abordagem:
- Usar CQRS para separar leitura e escrita
- Usar algo como MongoDB para leitura mais rápida dependendo do caso
Stack de Tecnologia
No começo da minha jornada em TI, eu trabalhava com PHP. Era a única linguagem que eu conhecia.
Quando comecei a trabalhar com processamento pesado em uma aplicação de imóveis, comecei a bater forte nos limites do PHP.
Na época, PHP não tinha bom suporte para async, multithreading, estruturas de dados eficientes, e as otimizações de garbage collector eram limitadas. Além disso, é uma linguagem interpretada.
Para resolver um problema específico, eu escrevi parte do processamento em C, que é uma linguagem compilada e muito rápida. Usei isso para rodar scripts que populavam o banco com arquivos CSV.
O que levava dias em PHP passou a levar minutos em C.
Isso me ensinou uma coisa importante: cada linguagem tem seu domínio.
Se você está lidando com uma aplicação grande ou com muito tráfego, precisa escolher a linguagem e o framework certos. Em alguns casos, faz sentido combinar abordagens — por exemplo, usar uma linguagem mais performática para endpoints específicos dentro de uma arquitetura maior.
Infraestrutura
Depois que o código está bem ajustado, eu olho para infraestrutura.
Perguntas que eu faço:
- O servidor tem CPU/RAM suficientes?
- O disco é um gargalo?
Depois penso em escala:
- Escala vertical (máquina melhor)
- Escala horizontal (mais instâncias + load balancer)
Latência e Localização
Localização importa mais do que parece.
Se os usuários estão em uma região e o servidor/banco está longe, a latência vai prejudicar.
- Manter API e banco próximos
- Usar CDN para distribuição global
- Usar banco distribuído geograficamente se necessário
Gerenciamento de Tráfego
- Usar load balancers para distribuir requisições
- Evitar sobrecarregar uma única instância
Era da IA
Faço brainstorming com o ChatGPT para gerar ideias e pesquiso técnicas em blogs com ajuda dele.
Ferramentas como Claude Code estão sendo usadas por pessoas como Linus Torvalds e Donald Knuth. Elas permitem fazer mudanças em minutos que antes levariam meses — mas precisam ser usadas com responsabilidade.
Até para este artigo, usei ChatGPT e Gemini para revisar gramática, lógica e coerência. E não tenho vergonha disso.
Conclusão
Para mim, tudo se resume a:
- Medir primeiro
- Resolver o gargalo real
- Depois escalar
Nem tudo precisa de Redis, gRPC ou CQRS. Às vezes o problema é só uma query ruim ou um bloqueio desnecessário.
Comments (0)
Leave a Comment
Be the first to comment!