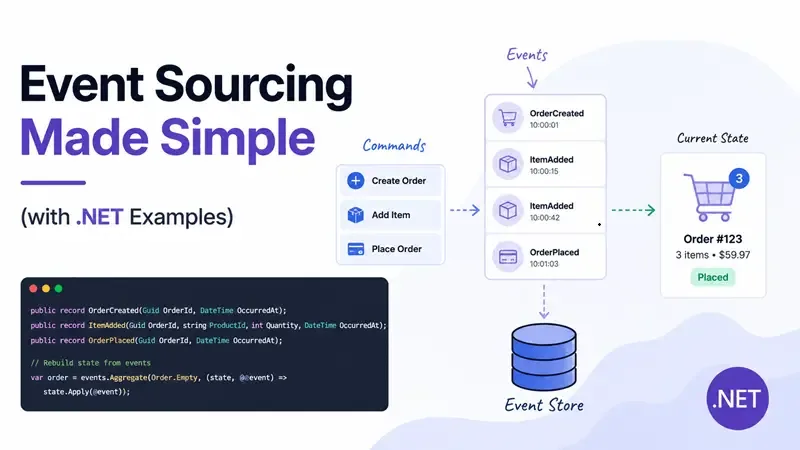
What is Event Sourcing?
Instead of saving the final state, you store events that, when processed, result in the final state.
That simple? Yes!
This concept can be expanded, but let’s start simple. Check this aggregate:
public class BankAccount
{
private decimal balance { get; set; } = 0;
List<Event> changes = new();
void When(Event @event)
{
switch (@event)
{
case Withdraw:
balance -= @event.amount;
break;
case Deposit:
balance += @event.amount;
break;
}
}
}
You can see that the state for attribute balance is defined by processing events instead of being retrieved directly from a database query. That’s Event Sourcing. We store objects (events) that represent state changes over entities.
In a banking system, we can create events such as:
- Withdrawn
- Deposit
- TaxApplied
- LimitChanged
- Transfer
- And many others
These events are stored in an event log, which can be a simple List<Event> or a more robust solution like an Event Store (people implement different approaches).
The most important concept in Event Sourcing is that the event log is immutable (IT IS OUR SOURCE OF TRUTH WHEN TALKING ABOUT STATE!). There are no updates or deletes. In practice, your database should enforce a policy that prevents UPDATE and DELETE operations on this table.
Performance
Imagine a bank account after 20 years with hundreds of thousands of operations, multiplied by millions of users. Replaying all events every time would create significant overhead.
That’s where design patterns come in to improve performance.
Projections
A projection keeps the current (final) state of an entity.
For example, every time a new event happens in BankAccount, you update a BankAccountProjection with the latest balance. So instead of recalculating everything, you always have a ready-to-use state. Every time a event happen you update the BankAccountProjection
If you suspect inconsistency, you can replay all events and rebuild the state for a projection, or even having different projections with different events computation. This process is called event replay.
Snapshot
How do you replay 500,000 events for millions of users efficiently?
You don’t. You use snapshots.
Every N events (e.g., 50 or 500), you store a snapshot of the current state, it save which aggregate version the snapshot was made and all the state for that aggregate.
When rebuilding, you start from the latest snapshot instead of from the beginning. For example, if a snapshot exists at event 550,000, you only replay the remaining events after that, because at that point the state was reliable.
This significantly reduces computation cost.
Cool things about Event Sourcing
- Supports offline-first applications (events can be synced later)
- Full audit history of all changes
- Ability to rebuild past states (time travel)
- Useful for analytics, data science, and big data
- Can simulate or project future states
- In the long run, you can use data science to make money by analyzing large amounts of event data and turning it into valuable insights.
Concepts people will talk about
Eventual Consistency
This is a conscious decision that data might not be immediately consistent, but will become consistent over time.
Example: You finish watching something on Netflix, but your phone still shows it as incomplete. After a few seconds, systems sync and the state becomes correct.
Optimistic Concurrency
- Add a
versionfield to the aggregate - Each event expects a specific version
Example:
A Withdraw event of $500 expects the account to be at version 203. When saving, the system checks the current version in the database.
If the version is not 203, an exception is thrown, and the user must retry the operation.
Tools in the .NET ecosystem
- Marten – A NoSQL database built for Event Sourcing with many built-in features
- Azure Cosmos DB – Reliable storage for events
- Azure Service Bus – Helps distribute events across systems
- MediatoR & CQRS - Helps easily notify events with separation of write and read operations
My all-time favorite Event Sourcing article
https://martinfowler.com/eaaDev/EventSourcing.html
When I was working as a contractor Software Engineer, I was basically desperate. I had to build a microservice using Event Sourcing with projections, and nothing made sense at the time.
After reading Martin Fowler’s article and seeing the “Ship” examples, everything started to click. It made so much sense that I didn’t even finish reading the whole article.
In just a week, I had:
- An event log in place
- State being built from event computation
- A projection storing the final state
That article was a turning point for me in understanding Event Sourcing in practice.
Event Sourcing Training
To reinforce and revisit these concepts in practice, I created training project focused on Event Sourcing using optimistic concurrency, projections, snapshot, cosmos DB Simulator, Azure Event Bus Queue.
The project was built for I training myself.
Comments (5)
Leave a Comment
I'm currently learning event sourcing this was helpful as a starting point
Hi kethireddy, here is Gabriel, you did the first comment in my blog, I'm glad it helped and comment system is working.
Agreed, that was really easy to digest a great overview to get the picture
nice breakdown
How did you managed to do this site so freaking fast does it use event sourcing? Please contact me have put my email in the form.
does this work with dapper or only EF
good for students but in real world we use marten
"The project was built for I training myself." Why you did to training yourself if you already know it?