How I Would Improve the Performance of a High-Traffic API
First thing, I don't want to simple scale in X or Y first, and also I don’t start changing code right away. I need to understand how the API behaves from START to the very END.
So I measure end points, because it could have bad performance database, CPU processing or even images .
I’d use tools like .NET benchmarking (Stopwatch is Bad), logs, graphics, insights from Azure Monitoring, Google Analytics and Cloudflare Dashboard to see what’s actually slow. No guessing here I want to know where time is being spent.
Understanding the Bottleneck
After that, I separate things into two main types:
- I/O operations
- CPU work
For I/O, I’m looking at things like:
- Database queries
- External API calls
- Disk/file access
For CPU:
- Loops
- Data processing
- Any heavy computation
This helps me understand where to focus.
Code-Level Improvements
Now I start improving the code itself.
If it’s I/O heavy:
- Make sure everything that can be async is actually async
- Avoid blocking threads
If it’s CPU heavy:
- Use parallel programming where it makes sense
Also important to see how many threads the CPU Server has to make use of Parallel.ForEach library
Using GPU for parallel programming it is a card for VERY EXTREME cases and I never needed to used it, but it's a rare field called GPU Computing for General Cases
I also review:
- Data structures (try to go from O(n) to O(1) when possible), and AI today can scan and help identify improvements.
- Memory usage and garbage collector pressure
- Instead using a class sometimes we can use record or struct
- Immutable data structures always give gains even if marginals but when 100.000 users hit API per second it make a difference (100k * 0.01)
Sometimes small changes here already give a big gain.
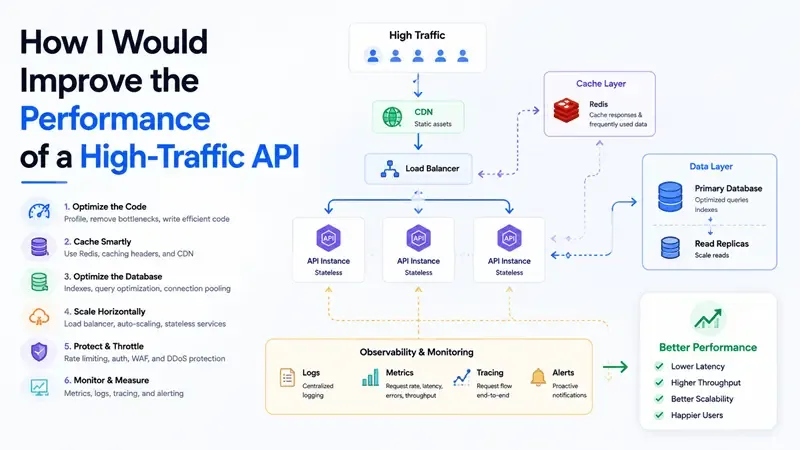
Reducing Load with Caching
If the API is being hit a lot, caching helps a lot.
- If you are scaling in horizontally then use Redis for distributed cache
- If you are just scalling vertically just cache all queries that don't change often using InMemoryCache from .NET
- Use static files if possible
- Use CDN such as Cloud Flare because it already has many speed tools such as webp conversion and optimization for images, http2 and 3 etc.
This alone can remove a huge amount of load from the system.
Payload and Communication
If the payload is too big, I look into reducing it.
In some cases, switching from REST to gRPC can help because it reduces payload size a lot (sometimes even around 40%).
Not always necessary, but it’s an option.
Database Optimization
A lot of performance issues come from the database.
- Analyze queries
- Rewrite them if needed
- Reduce unnecessary joins
- Check how data is being accessed
If needed, I can change the approach:
- Use CQRS to separate reads and writes
- Use something like MongoDB for faster reads depending on the use case
Technology Stack
In the beginning of my path in IT, I used to work with PHP. It was the only language I had experience with at the time.
When I started working on heavy data processing in a real estate application, I began to hit PHP’s limits pretty hard.
At that time, PHP didn’t offer strong support for async operations, multithreading, or efficient data structures. Garbage collection and performance optimizations were also limited, and on top of that, it’s an interpreted language.
To solve a specific problem, I wrote part of the processing in C, which is a compiled and very fast language. I used it to run scripts that populated the real estate database from CSV files.
What was taking days in PHP ended up taking just minutes in C.
That experience taught me an important lesson: each language has its own domain.
If you’re dealing with a large-scale application or heavy traffic, you need to choose the right language and framework for the job. In some cases, it makes sense to combine approaches for example, using a more performant language for specific endpoints or workloads, even inside a larger system architecture.
Once the code is in a good place, I look at infrastructure.
Questions I ask:
- Does the server have enough CPU/RAM?
- Is disk speed an issue?
Then scaling:
- Vertical scaling (better machine)
- Horizontal scaling (more instances + load balancer)
Latency and Location
Location matters more than people think.
If my users are in one region but the server/database is far away, latency will hurt performance.
- Keep API and database close
- Use CDNs for global distribution
- Use geographically distributed databases if needed
Handling Traffic
- Use load balancers to distribute requests
- Avoid overloading a single instance
AI Age
Brain storm with chatGPT ideas about how to improve and research from blogs with him techniques
Claude Code it's being used Linus Torvald and Donald Knuth, do with responsibility changes in a instant, where it would take a month
Even for this article, I asked ChatGPT and Gemini to review it and help me improve the grammar, logic, and coherence. I’m not ashamed of that, and people are reaching me.
Final Thought
For me, it always comes down to this:
- Measure first
- Fix the real bottleneck
- Then scale
Not everything needs Redis, gRPC, or CQRS. Sometimes the problem is just a bad query or a blocking call.
Comments (0)
Leave a Comment
Be the first to comment!